How to reduce latency in public clouds |
|
The cloud offers companies nearly every feature they need for managing their information resources: efficiency, scalability, capacity, affordability, reliability, security, and adaptability. What's missing from this list of cloud benefits is a deal-breaker for many organizations: performance.
A growing number of firms are moving mission-critical applications off the public cloud and back to in-house data centers because they need speed that the cloud infrastructure doesn't deliver. In a sponsored article on InfoWorld, HPE Cloud Group VP and Chief Engineer Gary Thome cites Dropbox as the poster child for big-name services that have turned their backs on the public cloud. The culprit, according to Thome, is time-sharing: Public cloud services may offer unlimited capacity, but their business model relies on capping performance. That's a problem you don't have when you manage your data systems, which you can generally scale up to whatever performance level your apps require. The public-cloud challenge: Accommodating apps with a low tolerance for latency Financial systems are the principal category of applications that require near-instant response to user and system requests. To address public-cloud latency, Thome suggests combining containers with composable infrastructure, which pools compute, storage, and network resources and "self-assembles" dynamically based on the needs of the workload or app. 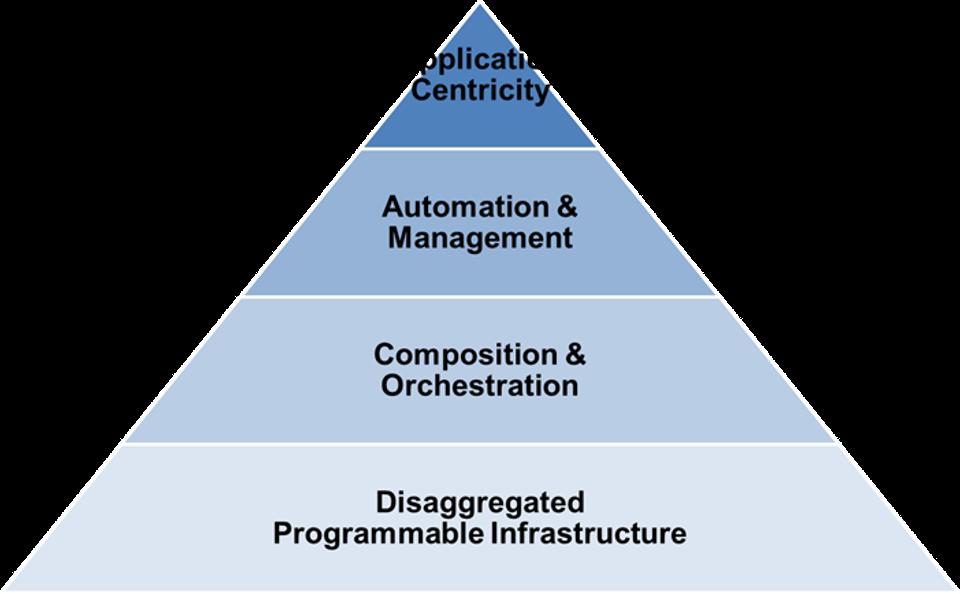 Four attributes of composable infrastructure are disaggregation of compute, memory, I/O, and storage; re-aggregation (composition) and orchestration; API-based automation and management; and matching apps to available resources to optimize performance. Source: Forbes Four attributes of composable infrastructure are disaggregation of compute, memory, I/O, and storage; re-aggregation (composition) and orchestration; API-based automation and management; and matching apps to available resources to optimize performance. Source: Forbes
By controlling the software-defined resources programmatically via a unified API, infrastructure becomes "a single line of code" that is optimized for that specific workload, according to Thome. The down side of a composable infrastructure approach is the loss of so many of the cost, efficiency, and speed attributes offered by the public cloud compared to management of on-premises data centers.
A more forward-looking approach is to address directly the causes of latency in systems hosted on the public cloud. That's the angle taken by two relatively new technologies: software-defined WANs and availability zones. A lingua franca for network management SD-WANs promise simpler network monitoring by accommodating a range of connections, including MPLS, broadband, and LTE. An SD-WAN's primary advantage is connecting between multiple cloud services and enterprise networks. The technology reduces latency by choosing the fastest path based on each network's policies and logic. TechTarget's Lee Doyle writes that SD-WANs will become more popular as companies increase their use of SaaS applications such as Salesforce, Google Docs, and Microsoft Office 365. An expensive alternative to dealing with latency on the public internet is to pay for direct interconnection, which offers direct links between multiple cloud services, telecom carriers, and enterprises. eWeek's Christopher Preimesberger lists seven criteria for comparing dedicated interconnection services to the public internet.
Morpheus: The low-latency alternative to expensive dedicated links The Morpheus cloud application management system offers a unique approach to guaranteeing high availability for latency-sensitive applications. Jeff Wheeler explains how the Morpheus Appliance's high-availability mode supports deployment in multi-tier environments. All of Morpheus's components are designed to be distributable to facilitate deployment in distributed-cloud settings to increase uptime availability. A stand-alone Morpheus configuration includes several tiers: web, application, cache, message queue, search index, and database. Each of these tiers except for cache is distributable and deployable on separate servers; cache is currently localized to each application server. A shared storage tier contains artifacts and backup objects. 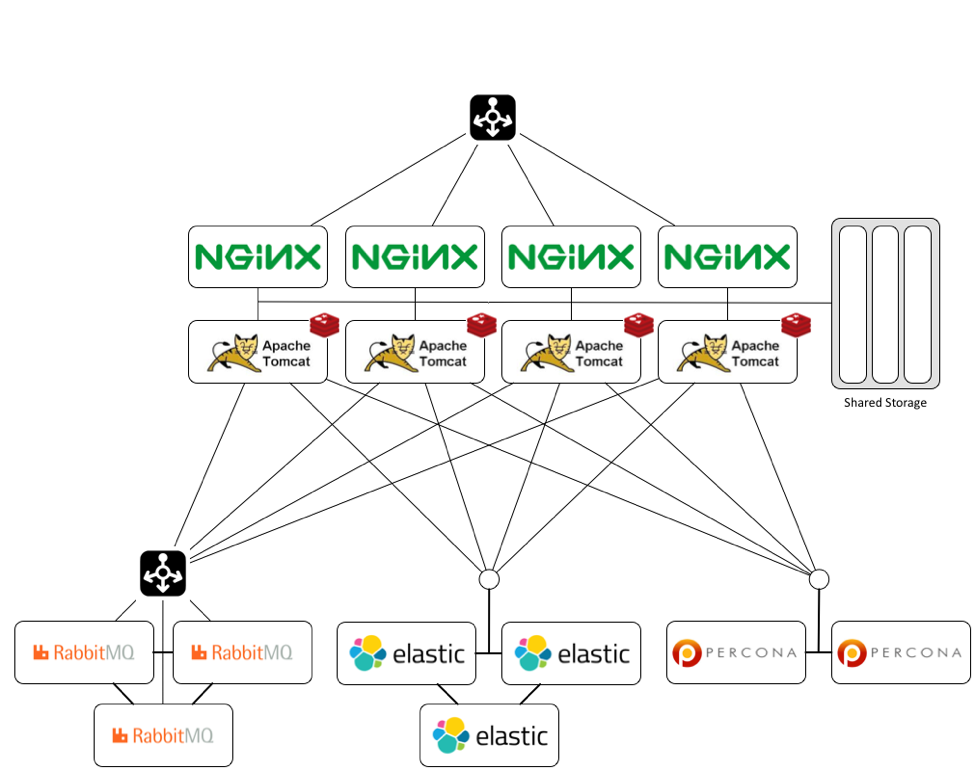 Nginx is used as a reverse proxy for the application tier, as well as for access to the localized package repository required for deploying data nodes and VMs. Source: Morpheus Nginx is used as a reverse proxy for the application tier, as well as for access to the localized package repository required for deploying data nodes and VMs. Source: Morpheus
For optimal performance, avoid crossing WAN boundaries with high latency links. In all other situations, external services can be configured in any cloud provider, on-premises cloud/data center, or virtual environment. The external load balancer that routes requests to a pool of web/app servers can be set to connect to each server via TLS to simplify configuration, but the balancer also supports non-TLS mode to support SSL offloading.
How edge networks increase rather than reduce the strain on cloud bandwidth Peter Levine, an analyst for Andreessen Horowitz, raised a lot of eyebrows last December with his presentation explaining why he believed cloud computing would soon be replaced by edge networks. Levine reasons that the devices we use every day will soon generate too much data to be accommodated by existing network bandwidth. The only way to make the burgeoning Internet of Things practical is by moving storage and processing to the edge of the network, where the data is initially collected. There's one element of edge networks Levine fails to address: management. Dan Draper of the financial services firm Vertiv writes in an April 17, 2017, article on Data Center Frontier that edge networks place data and processing in locations that IT departments can't access easily. Depending on the system, there could be thousands or even millions of such remote data points in a typical enterprise network. According to Draper, the solution to the bandwidth demands of IoT is creation of an integrated infrastructure. Network nodes will be like those nested Russian dolls, or "matryoshkas," scaling from smart sensors monitoring sewer lines and similar inaccessible spots, all the way up to public cloud installations processing terabytes of data in the blink of an eye. Draper points out two requirements for such an integrated infrastructure that remain works in progress: enhanced remote monitoring and power management. Services such as the Morpheus cloud application management system give companies a leg up by preparing them for "cloud" computing that extends all the way to the four corners of the earth. |
